Trong kỷ nguyên số, mọi thứ thay đổi với tốc độ chóng mặt, và những công nghệ từng là đột phá nhanh chóng trở thành một phần không thể thiếu trong cuộc sống hàng ngày. Hệ thống xác thực người dùng CAPTCHA là một ví dụ điển hình.
Khi bạn nhấp vào hộp kiểm 'Tôi không phải là robot', hành động tưởng chừng đơn giản đó lại ẩn chứa một hệ thống phức tạp phía sau. Nó là một phần của cuộc chiến không ngừng nghỉ giữa con người và các bot mạng độc hại.
Bài viết này sẽ đi sâu vào CAPTCHA là gì, nguồn gốc của nó, và tại sao các trang web vẫn cần đến CAPTCHA, reCAPTCHA hay 'Tôi không phải là robot' để bảo vệ người dùng và dữ liệu.
CAPTCHA là gì và tại sao nó là tuyến phòng thủ quan trọng?
CAPTCHA là viết tắt của “Completely Automated Public Turing test to tell Computers and Humans Apart” (Bài kiểm tra Turing công khai hoàn toàn tự động để phân biệt máy tính và con người).
Trong môi trường Internet hiện đại, nguy cơ tương tác với bot thay vì người thật là rất cao. Các bot mạng, được lập trình cho nhiều mục đích độc hại, đang ngày càng phổ biến. Chúng có thể được dùng để tạo tài khoản giả mạo, đặt vé hàng loạt, hoặc thậm chí dàn dựng các cuộc tấn công từ chối dịch vụ phân tán (DDoS) quy mô lớn. Những hành động này có thể gây thiệt hại nghiêm trọng cho doanh nghiệp, ngân hàng, và cả các trang web chính phủ. Để chống lại mối đe dọa này, việc có một cơ chế đáng tin cậy để phân biệt bot độc hại với người dùng thực sự là điều tối quan trọng. Đó chính là lý do CAPTCHA ra đời.
Sự ra đời và tiến hóa của CAPTCHA
Giống như nhiều cải tiến trên Internet, CAPTCHA có nguồn gốc từ cộng đồng hacker. Quay trở lại những năm 1980, hacker đã phát minh ra 'leetspeak' để vượt qua các lớp bảo mật trên diễn đàn trực tuyến. Leet là phương pháp thay thế các chữ cái bằng các ký tự hoặc số trông tương tự, khiến máy tính khó hiểu, ví dụ: 'leet' thành 'I33t', 'censored' thành 'c3n50red'.
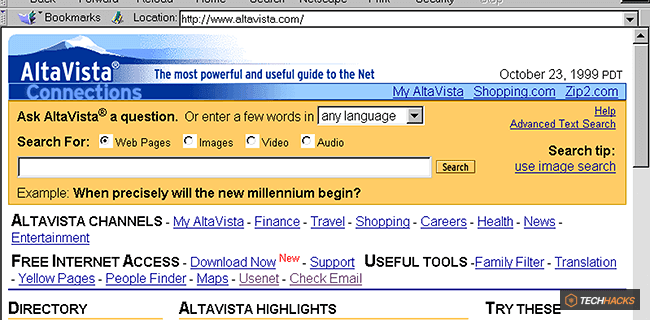
Vào thời điểm đó, các trang web được gửi thủ công đến các công cụ tìm kiếm. Dù việc gửi URL giúp mở rộng cơ sở dữ liệu, nhưng một số người dùng đã lạm dụng bot để spam máy chủ, thao túng thuật toán xếp hạng. Năm 1997, để ngăn chặn việc gửi trang web tự động, AltaVista – công cụ tìm kiếm hàng đầu lúc bấy giờ – đã triển khai một hệ thống tiền thân của CAPTCHA. Hệ thống này yêu cầu người dùng nhập một chuỗi ký tự bị bóp méo vào hộp văn bản. Kiểu CAPTCHA này dựa trên ba nguyên tắc cơ bản:
- Con người dễ dàng nhận ra các ký tự bị biến dạng, xoay hoặc lệch.
- Con người có thể phân tách các ký tự chồng chéo tốt hơn.
- Con người có khả năng đặt các ký tự vào bối cảnh trực quan để hiểu chúng là gì, ví dụ, xác định một ký tự dựa trên toàn bộ từ.
Thuật toán này, ban đầu được phát triển bởi Andrei Broder tại AltaVista, sau đó được hoàn thiện bởi các nhà nghiên cứu tại Đại học Carnegie Mellon, dẫn đầu là Luis von Ahn, vào đầu những năm 2000. Năm 2003, nhóm của von Ahn đã xuất bản một bài nghiên cứu tiên phong mô tả các loại chương trình phần mềm có thể phân biệt con người với máy tính, đồng thời đặt ra thuật ngữ CAPTCHA.
reCAPTCHA xuất hiện và cách nó biến người dùng thành 'nhân công'
Khi CAPTCHA ngày càng phổ biến trong bảo mật Internet, Luis von Ahn nhận thấy một vấn đề lớn: con người đang lãng phí quá nhiều thời gian để giải những câu đố này. Trong bài nói chuyện TED năm 2011, von Ahn ước tính rằng toàn nhân loại đã dành 500.000 giờ mỗi ngày để gõ CAPTCHA.
Với mong muốn CAPTCHA có thể được sử dụng hiệu quả hơn, ông đã phát triển reCAPTCHA, sau đó bán cho Google vào năm 2009. Ngày nay, nhiều dự án và công ty lớn như Google Books, Internet Archive, Amazon Kindle hay Thời báo New York đang quét và lập chỉ mục số lượng lớn sách, tài liệu và hình ảnh với sự hỗ trợ từ reCAPTCHA.
reCAPTCHA hoạt động bằng cách lấy những từ mà máy tính không thể nhận ra trong quá trình quét và ghép chúng với một từ đã biết. Người dùng được yêu cầu giải cả hai. Khi bạn nhập chính xác từ đã biết, hệ thống sẽ xác nhận bạn là người và tin tưởng rằng bạn đã số hóa chính xác từ thứ hai. Nếu 10 người khác cũng đưa ra đáp án giống bạn cho từ chưa biết, hệ thống sẽ coi đó là đáp án chính xác.

reCAPTCHA đã giúp số hóa hàng triệu cuốn sách mỗi năm và mở rộng hỗ trợ các nỗ lực khác như số hóa tên đường, số nhà trên Google Maps hoặc nhận diện đối tượng trong ảnh cho Google Images.

Ngoài CAPTCHA hình ảnh, còn có các dạng khác như CAPTCHA âm thanh (dành cho người khiếm thị, thường bị làm méo tiếng để chống phần mềm nhận diện giọng nói), câu hỏi văn bản mà máy tính khó hiểu, hoặc PiCAPTCHA yêu cầu người dùng chọn hình ảnh theo một thứ tự nhất định.
Sự ra đời của 'Tôi không phải là robot' - Bước nhảy vọt trong xác thực
Luis von Ahn từng tin rằng reCAPTCHA sẽ tồn tại mãi mãi vì “có rất nhiều văn bản in”. Tuy nhiên, trong kỷ nguyên Internet, không có gì là vĩnh cửu. Hệ thống CAPTCHA cũng không ngoại lệ.
CAPTCHA không phải là không thể phá vỡ. Năm 2014, phân tích của Google cho thấy trí tuệ nhân tạo (AI) có thể giải quyết các hình ảnh CAPTCHA và reCAPTCHA phức tạp nhất với độ chính xác lên tới 99.8%.
Để đối phó, Google đã tạo ra hệ thống mới: No CAPTCHA reCAPTCHA hay 'Tôi không phải là robot'. Công nghệ này không còn dựa vào khả năng giải mã văn bản của người dùng mà thay vào đó là phân tích hành vi trực tuyến của họ trước khi vượt qua điểm kiểm tra an ninh. Khi người dùng truy cập trang, thuật toán sẽ theo dõi cách họ tương tác với nội dung để quyết định xem đó là người hay robot.

Cụ thể, Google phân tích mọi thứ từ lịch sử duyệt web (bot độc hại thường không xem video YouTube hay kiểm tra Gmail trước khi đăng ký tài khoản) cho đến cách bạn di chuyển chuột trên trang. Nếu Google vẫn còn nghi ngờ về tính xác thực của bạn, sau khi nhấp vào hộp kiểm, bạn sẽ được hiển thị một thử thách reCAPTCHA trực quan (với các từ, biển báo đường phố hoặc hình ảnh) như một biện pháp bảo mật bổ sung. Cách tiếp cận đa diện này là cần thiết khi AI ngày càng thành thạo trong việc nhận dạng hình ảnh phức tạp, và với sự gia tăng của các 'trang trại CAPTCHA' (nơi các nhân viên được trả tiền để giải các câu đố CAPTCHA).
Cuộc chiến giữa các chuyên gia bảo mật và spambot sẽ không bao giờ có hồi kết. Công nghệ xác thực sẽ tiếp tục tiến hóa, và một ngày nào đó, 'Tôi không phải là robot' cũng có thể bị vượt qua và thay thế. Điều quan trọng là luôn cảnh giác và không ngừng cập nhật kiến thức về an ninh mạng.